岁寒输入法如何一统双拼和全拼?
前言
自岁寒拼音滑行输入方案问世以来,我对外的宣传口径一直都是“岁寒是双拼输入法的变种”,换言之,即岁寒是双拼的一个子集,他们的关系类似下图。
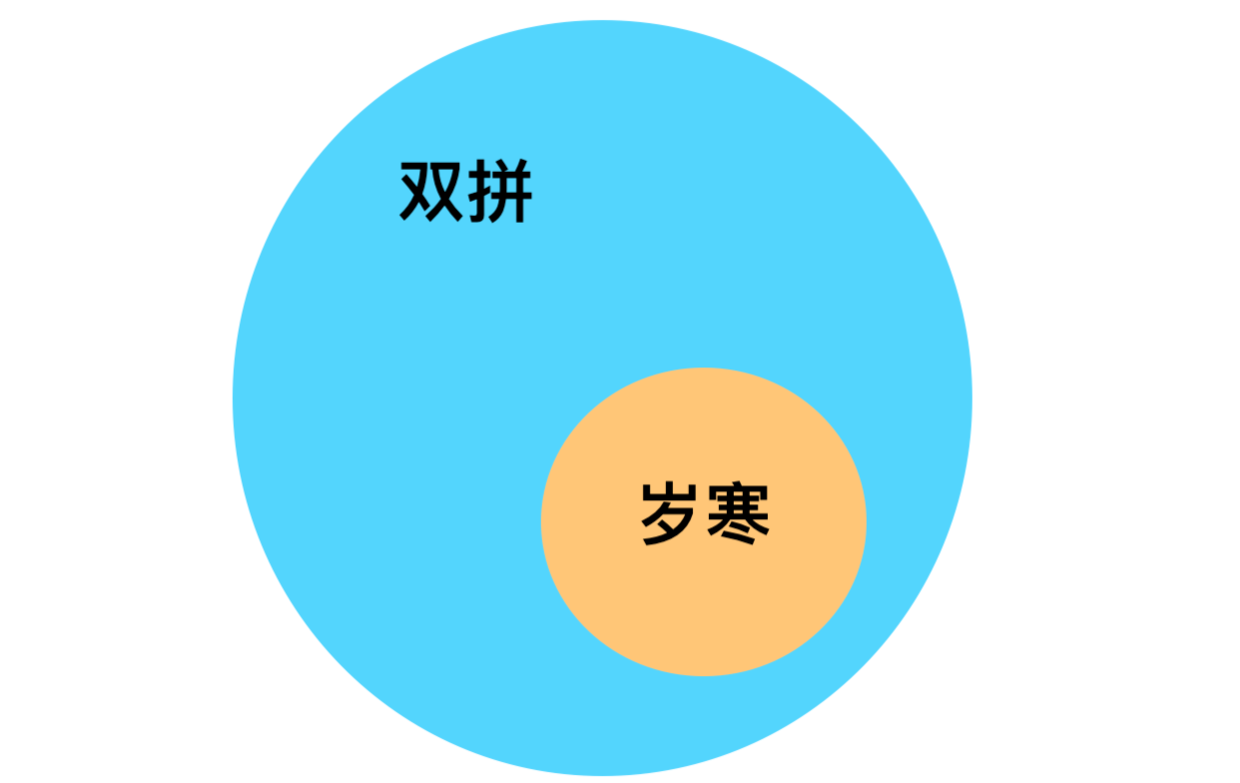
虽然有人建议我放弃这种说法,把岁寒宣传成全拼输入法的一种,如此更符合使用上的体验,也不会让新用户感觉过于陌生,滋生畏难情绪。毕竟岁寒确实与一般意义上的双拼有很大的不同,因此上述示意图并不能恰如其分地描述岁寒和双拼之间的关系,至少不应该是全包含的关系。但我自问,在设计岁寒输入法之初,更多从双拼输入法中汲取到了思想上的营养,所以我始终将岁寒视作双拼的一种,大体而言将岁寒视作双拼的一个子集,并无问题。 众所不知的是,双拼是一个相对小众的输入方案,很多人可能连双拼这个名词都不曾听说。而岁寒作为双拼的一个子集,则更是小众的小众,这严重限制了岁寒输入法潜在受众的基数。如何扩大岁寒的受众面也成为一直困扰我的重点难题。然而盲目地扩张功能以迎合更多用户需求的做法一直都是我极力反对的,所以我不曾听从那些让我加入全拼和九宫格方案之类的建议,我始终在极力避免岁寒输入法变得四不像,也在避免他泯然如众人。我相信一个输入法的发展要秉承一些贯彻始终的理念,具体的功能反而是次要的,但众多功能背后要传达的理念才是作品的根本。所以我始终在思考我要坚持的理念究竟为何? 从岁寒输入法的发展脉络来看,岁寒输入法1是滑行+图形识别+五笔,岁寒输入法2是滑行+笔画+五笔,岁寒输入法3以后的版本是滑行+双拼。可以看出的是,我想要坚持的并不是笔画、不是五笔,也不是双拼,不是某个具体的输入方案,而是滑行输入这件事情,我真正想要探问的,是滑行输入这个新维度究竟能给中文输入法世界带来多少及多深的改变?岁寒拼音的基本方案也好,韵母键族也好,前置路径也好,都是在为滑行输入这个目的服务。所以我也一直在思索,还有什么办法可以让岁寒在滑行输入这件事上做得更好,变得更强。
前置路径
随着我思考的加深,我把目光放到了前置路径身上。在设计前置路径之初,我对这个工具抱有巨大的期望。前置路径是对岁寒输入法已有的方案的继承和颠覆,因为他赋予了用户创造一套全新的滑行输入方案的能力。然而前置路径推出后,实际效果并没有我所期待的好。首先,是只有极少数几名岁寒输入法爱好者会去开发前置路径的潜能;其次,是他们所开发出来的新的滑行方案其实用者寥寥,很多使用者可能只是浅尝辄止,随后便将这些新方案束之高阁。是这些方案设计得很不好吗?也不尽然,爱好者们花费心思鼓捣出来的方案必然浸润他们的细腻心思在其中,一定有其出彩之处。但现实是,但凡有点学习成本,就足以将大多数人拒之门外。我需要为他们寻找破局的钥匙。我发现一个情理之中的现象,大多数基于前置路径开发出来的新滑行输入方案都是对传统双拼输入方案的复刻。遗憾的是,当前的前置路径并不能完美地复刻传统的双拼输入方案,这迫使设计者不得不采取折衷的做法,结果就是最终被设计出来的方案变成了一个强加上滑行效果的双拼怪胎方案,即便是原双拼输入方案的使用者也不一定能对之提起兴致。所以并不是岁寒输入法的爱好者们不够有创新精神,终究还是前置路径这个功能还不够强。在注意到这一点后,我问自己,既然爱好者如此希望复刻其他双拼方案,那我何不干脆就赋予他们这种能力?甚至是超越这种能力的东西。 在介绍我如何改进前置路径之前,读者需要了解岁寒输入法中的滑行路径表示法和前置路径要如何使用和配置,这里我就不浪费篇幅了,请移步以下参考材料自行阅读吧。 岁寒滑行路径表示法 岁寒输入法的前置路径功能的使用方法 岁寒配置文件的使用方法
双拼简介
在有了上述背景知识之后,我需要简单介绍一下双拼的背景知识。传统的双拼方案的输入思路是基于分时复用键盘键位实现的,我们可以简单的认为奇数次击键输入为声母,而偶数次击键输入为韵母。但分时复用其实不够,因为在双拼体系下,汉语拼音会被简单地拆分成声母和韵母两部分,声母的数量是23个,韵母的数量则是33个。众所周知,英文只有26个字母,我们当然可以轻易地将23个声母分配到26个键位上,但我们又该如何将33个韵母分配到26个键位上的呢?这不是还差7个键位吗?有的双拼方案会把;号键也利用上,但那也差了6个键位。把更多的非字母键位利用起来自然能解决问题,但显然这个解决方案并不优雅,实际上大多数双拼输入法也没有这么做的。那他们是怎么做的?这就要利用汉语拼音的另一个特点了——声母和韵母并不是可以任意组合的。也就是说,某些声母和某些韵母的组合在汉语拼音下是非法的,比如giao这个拼音就是没有的,虽然我们可以发这个音,但汉语里并没有与之对应的汉字,所以这个拼音是非法的。诸如此类的拼音还有很多,有些韵母之间甚至是互斥的,它们没有相同的可与之组合的声母。利用这一点,我们就可以让一部分存在互斥关系的韵母共享一个键位,从而将33个韵母分配到26个甚至更少的键位上。当我们点击一个存在韵母共享的键位时,输入法需要根据已经输入的声母来判断这个键位的实际释义。只要前置路径能够将上述的过程模拟出来,前置路径功能就具备完美复刻任何一款双拼输入法的能力。看到这里,不知道你是否已经猜到了我想做什么——我要给前置路径功能加上条件判断的能力。
带条件的前置路径
前置路径表示法
我将此前的前置路径的形式称为无条件的前置路径;

下面引入一个扩展后的表达形式,称为带条件的前置路径。

与此前的前置路径格式的区别就是在左边加上条件和**:**,并且在带条件时,要求最右边的输入部分可以是声母、韵母或者韵母的前缀,但不能是由声母和韵母组成的拼音。
条件的组成与要求
条件部分可以由以下要素组成:
- 任一声母
b p m f d t n l ɡ k h j q x zh ch sh r z c s y w和零声母(用数字0表示,关于零声母下文会详细讲解) **解释:**当条件声明为声母时,表示当前输入位置上存在且仅存在所声明的声母时,将指定路径接受为指定的声母或韵母,并输入到当前的输入位置上;示例如:
s:a=ang
//该式表示当当前输入位置为s时,点击a,
//在当前输入位置上输入ang,当前输入位置将变为sang;
(该条件的解释在拼音替入时存在例外,在优先级一节中介绍)
- 任一韵母或任一韵母的前缀;韵母的数量有点多,这里就不一一列举了。那什么是韵母的前缀呢?韵母的前缀就是由合法韵母从左到右若干个字母组成的字符串,即便不是合法的韵母也可以,如:iong的前缀:io、ion; **解释:**当条件声明为韵母或韵母的前缀时,表示当前输入位置上存在且仅存在所声明的韵母或韵母的前缀时,将指定路径接受为指定的声母或韵母,并输入到当前的输入位置上;示例如:
a:n=an
//该式表示当当前输入位置为a时,点击n,
//在当前输入位置上输入an,当前输入位置将变为an;
- 下划线+任一韵母或下划线+任一韵母的前缀,以an为例,则形如
_an;这里下划线表示韵母的左侧有声母(这里的声母包括零声母); **解释:**当条件声明为下划线+任一韵母或下划线+任一韵母的前缀时,表示当前输入位置上存在所声明的韵母或韵母的前缀,且存在任一声母,如所指定的输入为声母时,则将指定路径接受为该声母,并输入到当前的输入位置上;如所指定的输入为韵母且该韵母能与已存在的声母匹配时,则将指定路径接受为该韵母,并输入到当前的输入位置上;示例如:
_a:n=an
//该式表示当当前输入位置为形如xa的输入时,
//其中x表示任一声母,比如sa,点击n,
//由于an能与s匹配,因此在当前输入位置上输入an,
//当前输入位置将变为san;
优先级
前置路径之所以被我命名为前置路径,就是因为前置路径的优先级高于键位自带的键义,即当前置路径被触发时会覆盖键位本身的输入; 那现在前置路径有了无条件和带条件之分,为了避免歧义,需要对他们的优先级明确:带条件的前置路径优先于无条件的前置路径。即当带条件的前置路径和无条件的前置路径都被满足时,带条件的前置路径被触发,无条件前置路径不被触发;之所以如此规定,是因为如果无条件的前置路径优先级更高的话,则带条件的前置路径将无被触发的可能。 **在拼音替入操作中,允许声母条件在有韵母时被触发,这是声母条件的例外情况。**因此声母条件和下划线+韵母条件就可能存在冲突。 当带条件的前置路径中条件存在冲突时,下划线+韵母条件优于声母条件,即当下划线+韵母条件和声母条件同时被满足时,下划线+韵母条件被触发,声母条件不被触发。下划线+韵母条件和韵母条件在理论上不会发生冲突,因此他们是平级的。 优先级总结: 下划线+韵母条件前置路径=韵母条件前置路径>声母条件前置路径>无条件前置路径>键位自带键义
语法糖
- 条件的简写 为了便于描述多个条件下的同一路径的同一输入,允许在一条表达式中,用/分隔多个条件,如:
s/c/z/sh/ch/zh:a=ang
//该式表示当当前输入位置为s、c、z、sh、ch或zh时,点击a,
//在当前输入位置上输入ang;
- 反选声母的写法 当声母条件较多时,为了缩短条件列表,允许在需要排除的声母条件最前面添加~,表示选择所列出来的声母之外的其他所有声母作为条件,如:
~s/c/z/sh/ch/zh:a=ang
//该式表示当当前输入位置为s、c、z、sh、ch或zh之外的其他声母时,点击a,
//在当前输入位置上输入ang;
最极端的例子是全选所有声母:
~:a=ang
//该式表示当当前输入位置存在声母时,点击a,
//在当前输入位置上输入ang;
注意:反选写法仅适用于反选声母,不适用于反选韵母,列在反选条件列表的韵母条件将被忽略;换言之,韵母条件只能使用正选写法;有的小朋友可能会问,为什么韵母就不提供反选呢?因为我经过审慎思考认为,韵母条件他用不着反选。当然,如果有人能向我证明,韵母条件也存在需要反选的场景,我可以考虑加入。
双拼方案实践
前面我已完成了对带条件的前置路径功能的介绍,但显然这部分的文字表述有点多,对大部分读者来说,看完可能感觉有点晕头转向,为了便于直观地认识带条件前置路径的工作方式,下面我拿自然码双拼方案来演示一下如何使用带条件的前置路径功能来复刻他。
自然码方案
这里是自然码的键位表

有了这个键位表,我们就知道应该如何撰写表达式。这里我拿一个键位举例,比如键位s:

这个键位涉及两个韵母,一个是iong,一个是ong;
以iong为例,由于能与iong结合的声母只有j/q/x,因此表达式的写法是:j/q/x:s=iong;
以ong为例,能与ong结合的声母比较多,有ch/zh/c/d/g/h/k/l/n/r/s/t/y/z,因此表达式的写法是:ch/zh/c/d/g/h/k/l/n/r/s/t/y/z:s=ong,用反选写法则是:~sh/b/f/j/m/p/q/w/x/0:s=ong;
依次类推,我们便可以将自然码翻译的带条件的前置路径表示。
自然码中的特殊情况
在自然码中zh/ch/sh被分别映射到了v/i/u键上,因此我们需要这样写:
i=ch
u=sh
v=zh
此外,在自然码中,为了维持两键一字的原则,在当一个字没有声母时,用以下几个规则:
- 单字母韵母a,o,e重复按两次。如:a → aa,等。
- 双字母韵母an,en,ou等不变,直接输入。
- 三字母韵母ang,eng,重复第一个字母。如:ang → ah (双拼 h = ang)
我们一条一条来看:
- 单字母韵母a,o,e重复按两次。如:a → aa,等。 对于这种情况,我们可以这么写:
a:a=a
o:o=o
e:e=e
- 双字母韵母an,en,ou等不变,直接输入。 对于这种情况,我们可以这么写:
a:n=an
e:r=er
e:n=en
o:u=ou
a:o=ao
a:i=ai
e:i=ei
- 三字母韵母ang,eng,重复第一个字母。如:ang → ah (双拼 h = ang)
a:h=ang
e:g=eng
以上,就是自然码下带条件的前置路径的所有写法。整理之后,应该是下面这个样子:
~0:u=u
sh/zh/g/h/k:w=ua
~b/f/j/l/n/m/p/q/w/x/y/0:v=ui
j/l/n/q/x/y:t=ue
~b/f/j/m/p/q/w/x/y/0:o=uo
~b/f/n/m/p/w/0:p=un
sh/ch/zh/g/h/k:y=uai
~b/f/m/p/w/0:r=uan
sh/ch/zh/g/h/k:d=uang
l/n:v=v
~f/g/h/k/w/0:i=i
d/j/l/q/x:w=ia
b/d/j/l/n/m/p/q/t/x:x=ie
b/j/l/n/m/p/q/x/y:n=in
d/j/l/n/m/q/x:q=iu
b/d/j/l/n/m/p/q/t/x/y:y=ing
b/d/j/l/n/m/p/q/t/x:m=ian
b/d/j/l/n/m/p/q/t/x:c=iao
j/l/n/q/x:d=iang
j/q/x:s=iong
~j/q/r/x:a=a
~f/j/q/r/x/y:l=ai
~j/q/x:j=an
~f/j/q/w/x:k=ao
~j/q/x:h=ang
~b/f/j/p/q/w/x:e=e
~ch/zh/c/j/q/r/s/t/x/y:z=ei
~d/j/l/q/t/x/y:f=en
~j/q/x/y/0:g=eng
b/f/m/p/w/y/0:o=o
~b/j/q/w/x:b=ou
~sh/b/f/j/m/p/q/w/x/0:s=ong
i=ch
u=sh
v=zh
a:a=a
o:o=o
e:e=e
a:n=an
e:r=er
e:n=en
o:u=ou
a:o=ao
a:i=ai
e:i=ei
a:h=ang
e:g=eng
上述表达式中,为了使表示式不会过于冗长,针对不同的韵母,我取了正向选择写法和反向选择写法中较短的那种。 你可能会说:我写一条表达式,还得把声母和韵母的匹配关系全找出来,这也太麻烦了吧。这一点其实不必担心,因为声母和韵母的匹配关系是固定的,届时我会将完整的自然码方案的配置上传到在线配置上,这个配置就能体现所有的声母和韵母的匹配关系,你只需要根据你所需要的双拼方案的实际键位关系对这个配置进行修改即可;
针对拼音替入的优化
有了上述的配置,我们就可以在键盘上健步如飞地使用自然码进行输入了。但是如果我们现在想使用拼音替入,会发现由于带条件的前置路径的作用,输入的键位总是会受声母条件的影响被解释成韵母,这导致我们无法对已输入的声母进行替换。 为了岁寒输入法上的拼音替入功能能够更好地工作,还需要添加一些额外的表达式。这里我添加了每个键位的下滑路径为相应声母的无条件前置路径:
b4=b
c4=c
d4=d
f4=f
g4=g
h4=h
j4=j
k4=k
l4=l
n4=n
m4=m
p4=p
q4=q
r4=r
s4=s
t4=t
w4=w
x4=x
y4=y
z4=z
04=0
i4/i44=ch
u4/u44=sh
v4/v44=zh
其中,i44、u44和v44是为了防止用户滑行过头,导致误输入而加入的防御性操作,其他表达式之所以不加,是因为用户就算滑行过头,输入法会使用键位自带的键义作为输入,由此得到结果是一样的。
如此一来,当我们进行替入时,只要从相应的键位上下滑,就可以精准地替换掉想替换的声母。至于为什么要使用下滑而不是其他方向的路径,原因很简单,就是只有下滑这个方向是每个明键位都有的方向:最上面一行键位无法上滑,最左边的一列键位无法左滑,最右边的一列键位无法右滑,而最下面一行的键位由于还垫着一行操作键,有一行暗键位可供触发,下滑对于任何明键位都可以触发。
自此,我们已经能在岁寒拼音键盘上使用任意双拼输入方案了,并且能够愉快地使用既有的拼音替入、笔画筛选、截断优先、历史回溯等岁寒的特色功能。什么?你说岁寒拼音键盘用双拼不香!那用什么香?要用qwerty键盘才香!我告诉你!我,岁寒,就是死,就是从这里跳下去,也不会往岁寒输入法里加入……
给你你想要的真香
既然我们已经走上了复刻双拼方案的这条路,那固执与岁寒拼音的键位布局,让键位布局的因素影响到复刻最后的体验,是没有道理的,因此,我在引入带条件的前置路径的同时,还引入了qwerty布局。 但需要事先声明的是,在qwerty布局下,岁寒的拼音滑行方案是无法工作的。所以单纯打开qwerty布局并不能正常使用,需要配合具体的前置路径方案。
岁寒对qwerty布局的改进
想要让前置路径功能能够在qwerty布局上良好的工作,完全照搬常规的qwerty布局也不行,一些必要的调整不能少。这里,我将qwerty布局放到了3*10的规整布局中,效果如下:

由于部分双拼方案会使用到分号键,本来我是因为把这个键位也加上的。但我认为在已经有浮出子键盘的前提下,放一个分号键到键盘中几乎没有意义,于是我换了一个键值。眼睛尖的小朋友可能已经发现了,就是在一般放分号键的位置上居然放了一个0。不错,这里的0正是数字0本0,但这个键位不是用于输入数字0的,而是作为零声母的输入键。
岁寒输入法的爱好者可能才知道,在岁寒输入法中有一个叫虚声母的概念。这个概念是这样的,岁寒输入法认为所有汉语拼音都有声母,当然,官方制定的汉语拼音方案并非如此,所以小朋友们在考试的时候千万不要把这个观点写到试卷上,否则被老师打板子可别找我,事先声明啊。好,我们继续,既然岁寒输入法认为所有汉语拼音都有声母,原本就有声母的拼音还好说,那些实际上没有声母的拼音怎么办?岁寒输入法假设这些拼音里存在一个起到声母作用,但无法被输入的声母,这个声母我称作虚声母。有了这个假设,岁寒输入法便能做到省略声母。
现在,岁寒输入法干脆就将这个虚声母实例化,用0来代表这个声母。也就是说,虚声母现在是可以被输入的,为了以示区别,我借用了双拼方案里的说法,将其称为零声母。如果觉得不是很好理解,我举个例子,在岁寒输入法中,an不是an这个拼音的完整输入,而是被看作一个省略声母的输入,an的完整输入应该是0an。如今的零声母和此前的虚声母本质上没有区别,只不过以前的虚声母不可以输入,现在的零声母可以。而且在某些双拼方案中,我们确实需要一个能够表示零声母的符号。
助记功能
不少双拼用户在实际使用中少不了助记功能,这个新版本也提供了支持。比如我就在自然码的方案加入了该方案的相关助记:

助记功能的具体配置方法相对简单,这里就不赘述了,需要的朋友请参考岁寒配置文件的使用方法。
全拼实践
标题说要一统双拼和全拼,这会把讲完双拼,自然就轮到全拼了。 全拼的输入规则想必大家都清楚,我就不多赘述了,下面分情况和大家介绍如何用前置路径进行表示吧。
- 表示zh/ch/sh:
z:h=zh
c:h=ch
s:h=sh
- 表示长韵母,以uang为例:
u/_u:a=ua
ua/_ua:n=uan
uan/_uan:g=uang
可以看到,这里相当于是将韵母的变化情况用带条件的前置路径描述出来。uang属于所有前缀都是合法韵母的情况,但同时也存在一些韵母前缀不都是合法韵母的情况,比如iong。但没有关系,带条件的前置路径一样可以描述:
i/_i:o=io
io/_io:n=ion
ion/_ion:g=iong
前面两个例子中都是韵母条件和下划线+韵母条件的情况,但并不是非得这么写不可的,这么写只是在不影响实际使用的前提下加入的方便输入,考虑到io、ion、iong一般不会省略声母,所以写成:
_i:o=io
_io:n=ion
_ion:g=iong
也是对的。 以此类推,我们就可以得到全拼的前置路径表示:
z:h=zh
c:h=ch
s:h=sh
a/_a:n=an
an/_an:g=ang
a/_a:i=ai
a/_a:o=ao
o/_o:n=on
on/_on:g=ong
o/_o:u=ou
e/_e:n=en
en/_en:g=eng
e/_e:i=ei
e/_e:r=er
i/_i:n=in
in/_in:g=ing
i/_i:a=ia
ia/_ia:o=iao
ia/_ia:n=ian
ian/_ian:g=iang
i/_i:e=ie
i/_i:o=io
io/_io:n=ion
ion/_ion:g=iong
i/_i:u=iu
u/_u:n=un
u/_u:a=ua
ua/_ua:n=uan
ua/_ua:i=uai
uan/_uan:g=uang
u/_u:o=uo
u/_u:e=ue
u/_u:i=ui
v/_v:e=ue
b4=b
c4=c
d4=d
f4=f
g4=g
h4=h
j4=j
k4=k
l4=l
n4=n
m4=m
p4=p
q4=q
r4=r
s4=s
t4=t
w4=w
x4=x
y4=y
z4=z
04=0
i4/i44=ch
u4/u44=sh
v4/v44=zh
与双拼类似的,我加入了下滑输入声母的前置路径,同样是为了优化拼音替入效果。
现在我们就可以在岁寒上使用全拼输入方案了。同样的,我们在使用的全拼的同时,也可以享受到岁寒输入法的各种特色功能,如笔画筛选(加形可能就不是很有必要了)、拼音替入、截断优先、历史回溯等等。
但这个实现方案下的全拼存在一个瑕疵,就是在输入n或g时,可能出现前一个拼音将n或g“夺走”的情况。比如我们想要输入“可能”的拼音,按拼音顺序输入是“keneng”,此时,岁寒输入法会识别得到“ken’eng”,而不是一般全拼输入法的“ke’neng”。这是因为这种组合本身是存在歧义的,一般的全拼输入法会根据拼音频率选择更常见的“ke’neng”。而岁寒是按顺序接受输入的,考虑到路径n和韵母条件e满足带条件的前置路径表达式:e/_e:n=en,而k又正好能与en匹配,从而触发了表达式,所以这种结果本身是没有毛病的,只是与我们日常的使用习惯不太相符。那这种情况要如何解决呢?方法是在可能出现这种情况的地方使用下滑输入n或g,这样就可以避免触发e/_e:n=en表达式。我知道这种建议有点类似与苹果公司建议用户换一种手机持握方式,此种情形的存在其实是岁寒输入法的设计逻辑和全拼拼音方案不相契合导致的,因为岁寒是拒绝歧义的,而全拼却又不可避免的存在歧义。如果可能的话,我会引入一些机制来纠正这种情况。
使用全拼时的建议
如果使用全拼输入方案的话,可以在输入设置中将删除键的操作改为以字母为删除单位,这样会更加符合全拼下的实际使用习惯。
写在最后
带条件的前置路径功能自此已介绍完毕。岁寒输入法通过带条件的前置路径功能将双拼输入方案和全拼输入方案收到了麾下,在一套体系下一统了岁寒拼音、全拼和双拼方案。据我所知,还有人在探索诸如三拼方案之类的拼音方案,而类似的方案也能通过带条件的前置路径实现。从某种意义上,岁寒输入法已彻底进化为一个平台化的输入法,是拼音输入方案的一个超集。
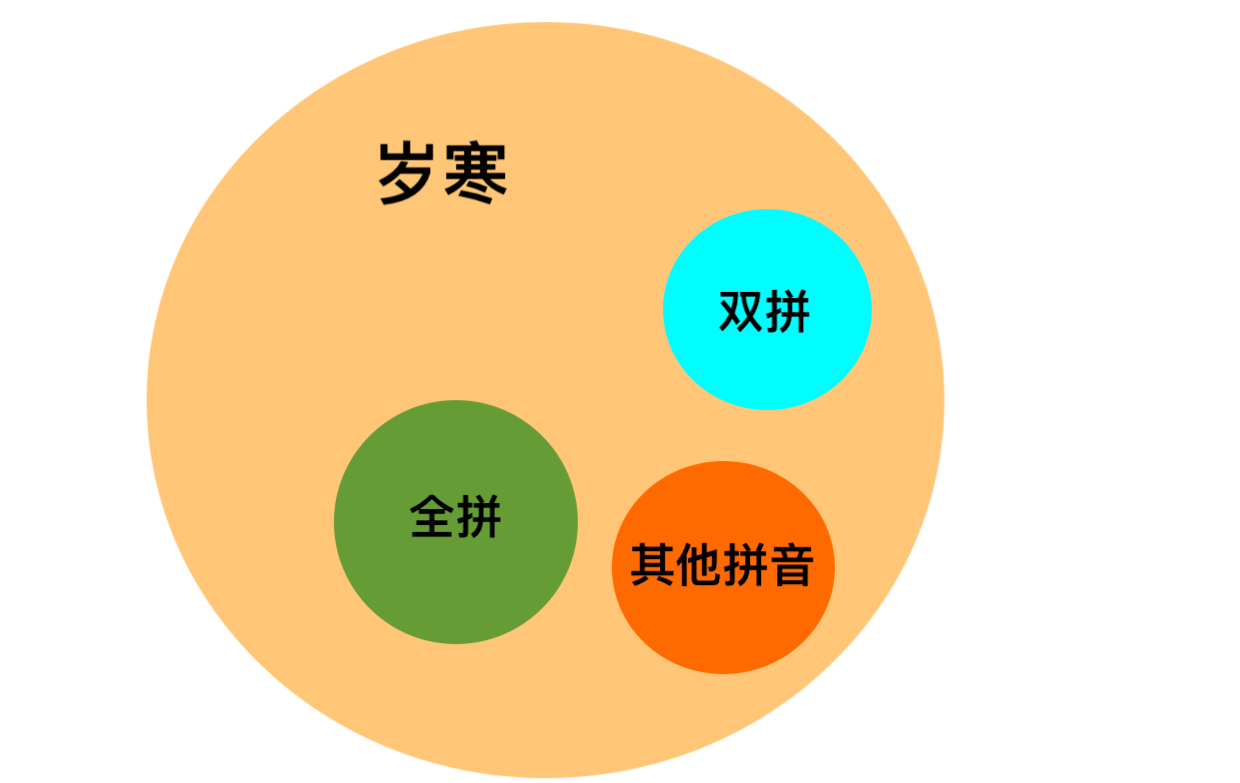
用户可以通过导入相应的配置文件来获得与之高度契合的体验,此外也能享受到岁寒输入法种种独特功能,这就达成了一种效果——方案之间各有特色,但操作上又彼此统一。
如果您觉得岁寒的带条件的前置路径确实不错的话,请将“岁寒,YES”打在讨论区。感谢您的支持。
- 原文作者:岁寒
- 原文链接:http://www.suihanime.com/post/%E5%B2%81%E5%AF%92%E8%BE%93%E5%85%A5%E6%B3%95/%E5%B2%81%E5%AF%92%E8%BE%93%E5%85%A5%E6%B3%95%E5%A6%82%E4%BD%95%E4%B8%80%E7%BB%9F%E5%8F%8C%E6%8B%BC%E5%92%8C%E5%85%A8%E6%8B%BC/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。